Alice and Bob want to share some bits of key
To protect their messages from Eve- the adversary
Alice encodes the bits as follows
In standard basis if heads is up and H basis if tails shows
Now Bob measures in a random basis
Verifying half the bits they check if Eve left her traces
They use the other half of matching bits if they succeed
And use the key shared securely indeed !
Quantum Poetry VI : CHSH game
Alice and Bob just shot to fame
After succeeding in CHSH game
None at all could match their wits
In producing Xor of outputs as And of input Bits!
Alice measured in X basis on input 0 and Z on input one
Bob measured in plus minus pi by 8 basis in his turn
They won with probability zero point eight five
Classical players winning three out of four times seemed so naive!
Quantum Poetry V : Bernstein Vazirani Algorithm
An oracle linear function is what you’ve got
The weights of the function are now sought,
Convert the oracle to a phase
Using the ket minus state the same old ways!
Create a uniform state and be quick,
Use the Hadamards our favourite trick!
Apply the phase oracle and Hadamards again
And your efforts will not be in vain
The measured bits are the weights
With probability 1, irrespective of fate!
Quantum Poetry IV : Deutch Josza Algorithm
Given an oracle to a function
Balanced or constant is the main question
If the oracle is quantum , do not wait
Bring the ancilla to ket minus state!
Bring the input qubits to uniform state indeed
A bunch of Hadamards is all you need
Multiplication by phase is now the oracle’s action
Measure now to all 0s for constant function
If you measure non zero then you just got
A balanced function in your lot!
Quantum Poetry III : Grover’s search
If you want to search for a marked element,
You can do it on root N time , so do not lament
Prepare a statevector in uniform state
An easy way to do so is using just Hadamard gates
Now iterate between the two steps below
(1)Apply oracle and the reflected state shows
(2) Reflect about initial state which rotates the state
The above 2 steps completes 1 Grover’s iterate
Increase the angle (using the 2 steps ) and finally perform a measurement
With high probability you’ll get the marked element
Quantum Poetry II : Classical interpretation of Quantum Teleportation
This poem is based on the classical interpretation of quantum teleportation which is discussed in this lecture here (https://www.youtube.com/watch?v=q1zFVFJV_Ug)
Quantum teleportation about which you tell,
Has a nice classical interpretation as well
Replace the Hadamard with classical randomizing gate (One which creates a uniform classical state),
And then as usual measure after applying CNOT
Player 2 applies an X and classical OTP is what you got!
Quantum Poetry I : Quantum Teleportation
If you want to teleport a quantum bit you’ll need an EPR pair
Apply CNOT and Hadamard to your share
Next step is to measure the qubits
The classical outcomes you’ll need to transmit
Let the other player apply X and Z gates
The qubit is transmitted (deterministically) irrespective of fate!
कोरोना का कहर-धीरज मदान
शुरू हुआ एक ही नर से
फैल गया विश्वभर में
ले डूबा सबको जैसे कोई लहर
छा गया कोरोना का कहर।
फैले यह वायु से
फैले यह सतह छूने से
हर जगह है इसका ज़हर
छा गया कोरोना का कहर।
काम करलो सारे घर बैठे
मंगवालो सब कुछ ऑनलाइन फल या पेठे
जहाँ हो वहीं पर ठहर
क्योंकि छा गया कोरोना का कहर।
कम हुआ कुछ ट्रैफिक
कम हुआ कुछ प्रदूषण
साफ़ हुए नाले व नहर
छा गया कोरोना का कहर।
फैल गया यह हर शहर
समय न देखे – सं ध्या या सहर
खतरा इसका आठों पहर
छा गया कोरोना का कहर।
न इसकी दवा या कोई टीका
रंग पड़ जाये सबका फीका
वैक्सीन बन जाये अगर हो रब की महर
और अंत हो जाये यह कोरोना का कहर।
Modelling pairs of sentences through deep learning (old post)
There are several problems in natural language processing which involve modelling a relationship between pairs of sentences such as:-
- Paraphrase Detection: Are two given sentences A and B paraphrases of each other ?
- Sentence Similarity: Another variation (1) could be to output a similarity score between the two sentences (a higher score would indicate more similarity).
- Semantic Entailment or Natural Language Inference: Given two sentences A and B , we need to determine if there is a semantic relationship between the two such as does A entail B or A contradicts B or if A is neutral to B
Recently there have been several models in deep learning which are based on the following high level approach:-
- Get vector representation of both the sentences
- Use a distance function or a classifier to predict the relationship for the appropriate task

These approaches however differ in the way the representation of the sentences is produced and the choice of classifier or distance function. The following diagram shows a taxonomy of several approaches which people have used.

One possibility would be to create the vectors by training on a different task. Kiros et al consider the task of predicting the neighbouring sentences from the current sentence on a book dataset. Specifically they use an LSTM based encoder decoder based network to do so. The vectors so produced are then used several different tasks including paraphrase detection and semantic entailment.
Another possibility would be to learn these vectors in an end to end manner. Thyagarajan and Mueller consider a network wherein they encode two different sentences using RNN and then have a similarity function which builds upon the encoded representations.

Specifically they run two LSTM based RNNs to obtain a representation of the two sentences. An exponential of negative L1-norm distance was used to predict a similarity score between the two sentences. The two LSTM here have tied parameters. This entire network can be trained end to end.
Well, now lets consider some variations of the above network. Tai, Socher and Manning had introduced tree LSTM networks to capture syntactic information from constituency and dependency parse trees. Specifically they proposed two kinds of networks:-
- Child-Sum Tree LSTMs : Here there is an LSTM unit at each node of the tree. The state at in internal node is computed from the state of the child nodes. The child states are summed up to obtain an intermediate state. This intermediate state acts as the previous state which is then updated to the new state as in standard LSTMs. The above is ideal for a setting where each node can have a variable number of children, as in a dependency tree.
- N-ary Tree LSTMs: A second alternative proposed by them is to restrict the model to trees with nodes having a fixed number of children each. Here instead of summing up the hidden representation of each child the model considers a different weight matrix for each child’s representation. This setting is suitable for the case of a constituency parse tree.
The representation at the root forms the representation of the sentence. After obtaining the same one can use a classifier at the top. Specifically they create features as term-wise product and difference of the elements of the two encoded vectors which are then used as input to a softmax classifier.
Another idea which has been explored is that of attention. Parikh et al argue that it suffices to consider local alignment between word embeddings of 2 sentences without using any deep or complex representation. They propose the following approach for the task of natural language inference on two sentences a and b with words embeddings (a1,a2,…) and (b1,b2,…).
- Align each word embedding in sentence 1 with the words embeddings in sentence 2 and vice versa
- Next use a feed forward network which compares the aligned phrase with original sentence to obtain a score vector for each position i in sentence 1 and position j in sentence 2
- Aggregate the score vectors across the 2 sentences using sum-pooling. Use a feedforward network which takes the aggregated vectors and outputs a prediction for each inference class
The entire network can be trained in an end to end fashion. The above model has the advantage of being parallelizable.
There have been several extensions to the above attention based mechanism. Chen et al use attention to enhance the representation obtained through tree and chain LSTMs. Zhou, Liu and Pan use RNNs to guide the encoding of tree-LSTMs. Recently Conneau et al obtained universal sentence representation by training on the above tasks. These would be described in the next blog post.
A Neural HMM for creating dialog workspace
There are two general approaches to design an automated conversational system:-
- Deep Learning based approach : In this approach a deep learning model is trained on the task of generating a response given the dialog context in an end to end manner . This has the advantage that the training can be completely automated. However, the problem here is that the model is not interpretable and this will not be suitable for critical applications.
- Rule based approach : In this approach a dialog workspace (such as Watson Assistant, Dialog Flow or Bot Framework ) is created manually. The workspace can be considered as a finite state machine with a discrete set of states representing the possible “states” where you can be in a conversation and a set of edges connecting theses states . These edges are labelled by intents which represent the classes of user utterances. Each dialog state is also associated with a response (or sometimes a set of response variants). At run time, the system receives a user utterance, classifies it into one of the intent classes ,makes a transition to one of the states (with an edge labelled by the classified intent) and generates the response corresponding to the new state. Now this kind of system is interpretable . However it requires a great deal of manual effort to create this system.
Ideally our goal would be to create a dialog workspace with least amount of manual effort. In one of my previous blog posts , I had discussed the problem of finding dialog workspace #intents from conversational data in an automated manner. Here I will discuss an approach to create a rudimentary work space in an end to end manner. The workspace can then be improved with small amount of manual effort.
For the above task, we have designed a deep learning model with discrete states which I will be describing here. I will also discuss our algorithm to train the above in an efficient manner.
We denote a dialog as D with a sequence of utterances 

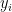


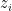

This state variable 

The Transition Distribution: Here, we need to model the probability of observing a new state 


The Emission Distribution: Given the current state 


An illustration of the flow of dialog using our latent state tracking network is shown in figure below:-

A graphical model representation of LSTN is given below:-

The joint distribution of the agent responses y = (y1, . . . , yN ) and the belief states z = (z1, . . . , zN ) given the user utterances x = (x1, . . . , xN ) for a given conversation can be written as:

The training now constitutes maximizing the log likelihood 
I will discuss this training algorithm in the next blog post.
